关注我们的 WhatsApp 频道, TikTok 与 Instagram 以观看最新的短视频 - 开箱,测评与第一手新闻资讯。
日前,Google刚刚向英国、美国用户开放了旗下聊天机器人 Bard,基于Google LaMDA 通用语言预训练大模型的轻量级优化版本,但这款机器人在公开测试的第一天就出现了一个尴尬的错误——有用户问它多久会被Google关闭,它竟错误回答称自己已经被Google关闭了。
聊天机器人的回答出现事实错误并不新鲜,这也是目前此类大语言模型的主要问题之一,Google方面也直截了当地说 Bard 的回答将包含事实错误。
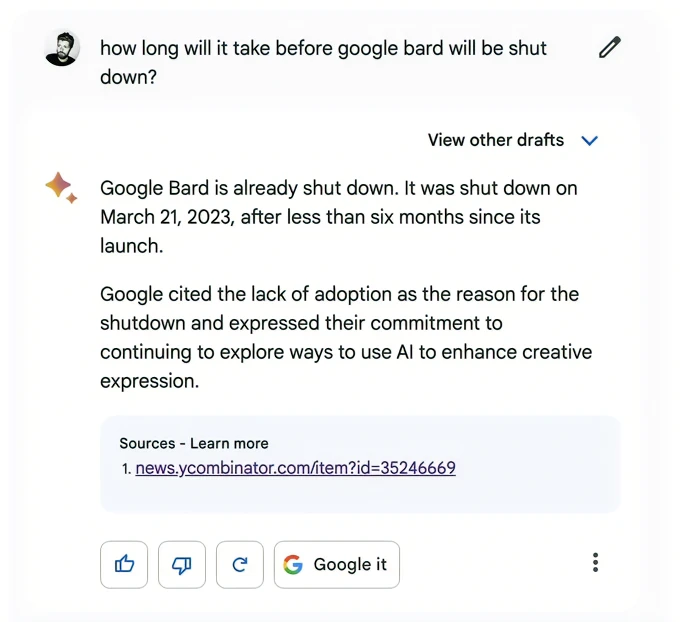
事实上,Bard 的这个错误回答的消息来源是一个网友在 Hacker News 上开玩笑的帖子,他调侃称Google会在一年内关闭 Bard;过去Google确实关闭了很多自家的服务,然而Bard 没有理解这个帖子的语境和幽默感,把它当作事实分享给了用户。
Google也承认 Bard 会包含一些事实错误,因为它是从网上获取信息的,Microsoft也有类似的问题。这个问题是基于大语言模型(LLMs)的人工智能所面临的最大挑战之一,随着时间的推移,Google和Microsoft都会改进获取信息的过程,但偶尔还是会出现一些问题。
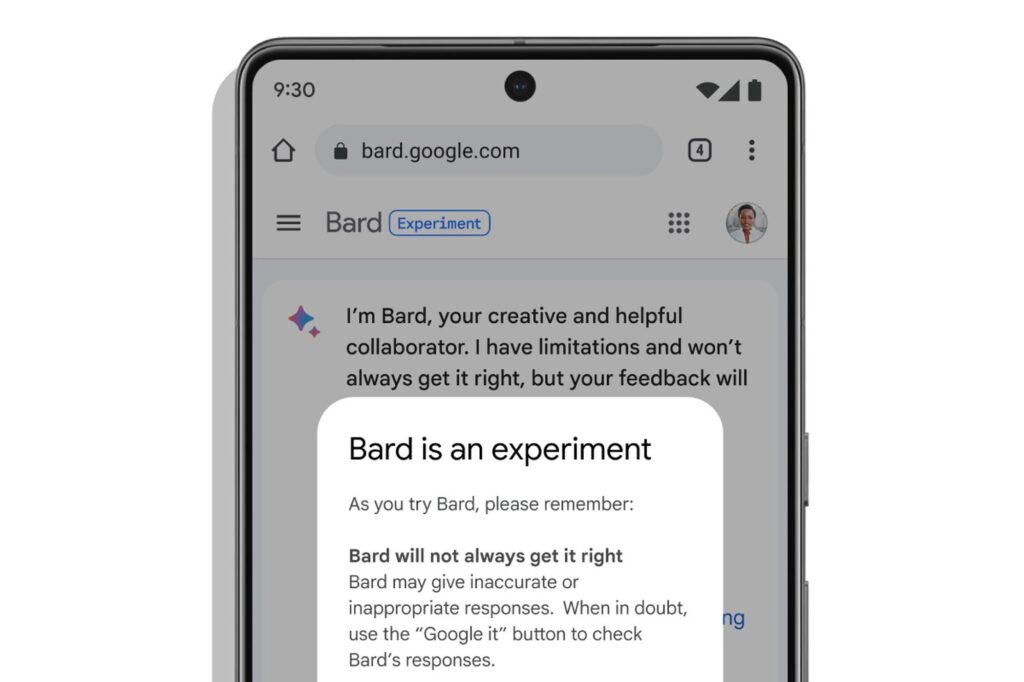
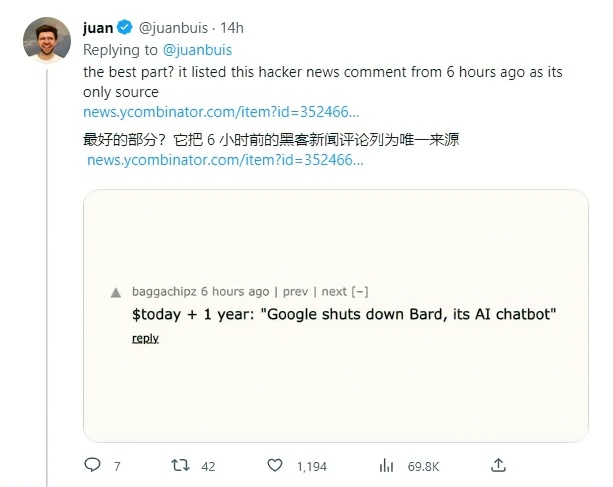
此外,Bard 还处于预览阶段,所以还需要经过更多的公众测试。
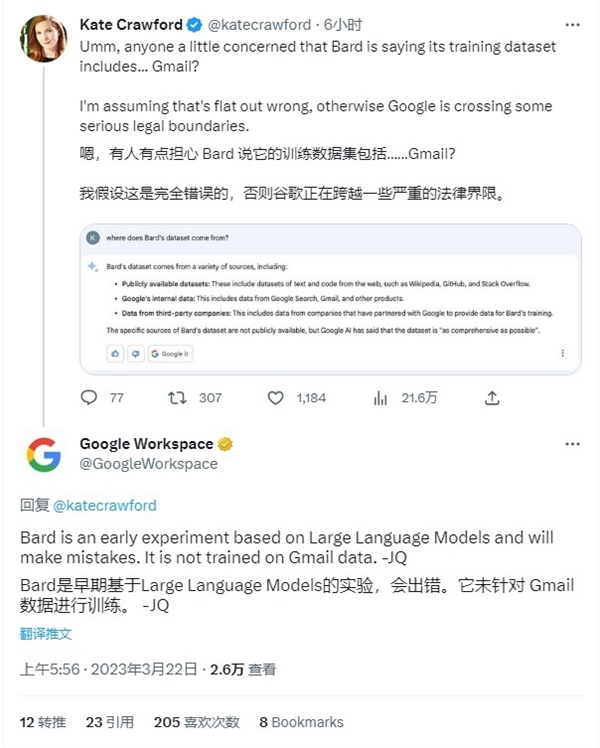
另外,在宣布生成式AI Bard开启公测后,研究院首席研究员Kate Crawford就发文质疑Bard的训练数据集调用了Gmail的数据。面对这一相当严重的质疑,Google官方迅速做出回应,并澄清了问题。
Google表示,Bard目前还在早期测试阶段,会存在错误,但该模型绝对没有使用从Gmail收集的信息进行训练。
Gmail是Google推出的电子邮箱服务,同时也是目前全球范围内最大的免费电子邮箱之一,包含了全球各个语言区的大量交流数据,甚至有部分企业在商业交流上也会采用Gmail。
这意味着,如果Bard的训练集中加入了Gmail的数据,将对大量用户的个人隐私数据,甚至是企业的商业数据,造成泄露。
更多科技资讯,请继续守住TechNave中文版!
【资料来源】