关注我们的 WhatsApp 频道, TikTok 与 Instagram 以观看最新的短视频 - 开箱,测评与第一手新闻资讯。
DeepSeek最新发布的V3.1语言模型近日被发现存在技术上的缺陷。在生成程序代码时,模型会意外插入中文字符“极”,从而导致输出结果异常,严重影响其在编程领域的可靠性。
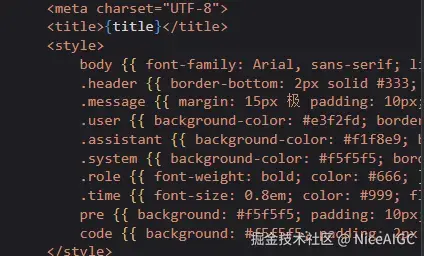
多位开发者在不同平台的测试中均遇到类似问题,显然这并非个别现象。一名开发者在进行DeepSeek V3.1测试时指出,模型在生成简单代码片段时频繁出现异常。例如,当系统应输出“time.Second”时,却错误地生成了“time.Se极”,在英文代码中插入了不相关的中文字符。

从多个测试结果显示,该问题会出现在多个环境下,其中包括了本地llama.cpp推理引擎与Fireworks平台上的FP8全精度模型。进一步调查发现,这些中文字符在完全无关的上下文中被赋予了异常高的概率,导致输出错误。
不仅如此,DeepSeek系列的旧版本V3 0324也有类似的问题。除此之外,Alibaba旗下的Qwen系列模型中的235B A22B Instruct 2507和Qwen3 Coder 30B A3B Instruct同样被发现存在相同缺陷。不过,ZHIPU AI的GLM 4.5模型暂未受到影响。
有开发者认为,这些模型可能使用了相同的“受污染”训练数据,才导致在生成代码时出现跨语言字符的混淆情况。
为了确定此项问题不是源于特定的推理工具,开发者还在Fireworks、Novita等不同平台进行了测试,结果均出现相同错误,进一步确认问题可能源自模型本身。开发者也推测出此项问题极有可能与MTP(Mixed Token Prediction)技术有一定关联,因为此问题在不支持MTP的推理堆叠中更加明显。
专家表示,这类跨语言字符混淆问题凸显了当前大语言模型在训练和数据清理环节仍有改进空间。对于需要高度精确的代码生成任务,这种异常会导致程式错误或编译失败。随着越来越多企业依赖AI辅助编程,确保模型输出的准确性与稳定性非常重要。
更多科技资讯,请继续守住 TechNave 中文版!
【资料来源】